Runyu Lu
SenseTime internel Share 2023.09.05
What is MLIR
Multi-Level Intermediate Representation instead of Machine Learning Intermediate Representation.
What is IR
深度学习中的 IR 只是一个深度学习框架,公司甚至是一个人定义的一种中介数据格式,它可以表示深度学习中的模型(由算子和数据构成)那么这种格式就是 IR。
比如ONNX,ONNX 是微软和 FaceBook 提出的一种 IR,他持有了一套标准化算子格式。无论你使用哪种深度学习框架(Pytorch,TensorFlow,OneFlow)都可以将计算图转换成 ONNX 进行存储。然后各个部署框架只需要支持 ONNX 模型格式就可以简单的部署各个框架训练的模型了,解决了各个框架之间模型互转的复杂问题。
比如TVM中的Relay IR, 这是一个函数式、可微的、静态的、针对机器学习的领域定制编程语言。Relay IR 解决了普通 DL 框架不支持 control flow(或者要借用 python 的 control flow,典型的比如 TorchScript)以及 dynamic shape 的特点,使用 lambda calculus 作为基准 IR。 当然现在TVM社区主要在开发Relax IR,这个相比于Relay更加灵活,而且更加原生支持dyn_shape
包括更加底层的TVM Tensor IR, 也是一种IR。
The Challenge
ppt from: https://www.bilibili.com/video/BV1Wp4y1z72d/
推荐观看这个视频,这个视频把MLIR Lower的过程讲的非常形象。
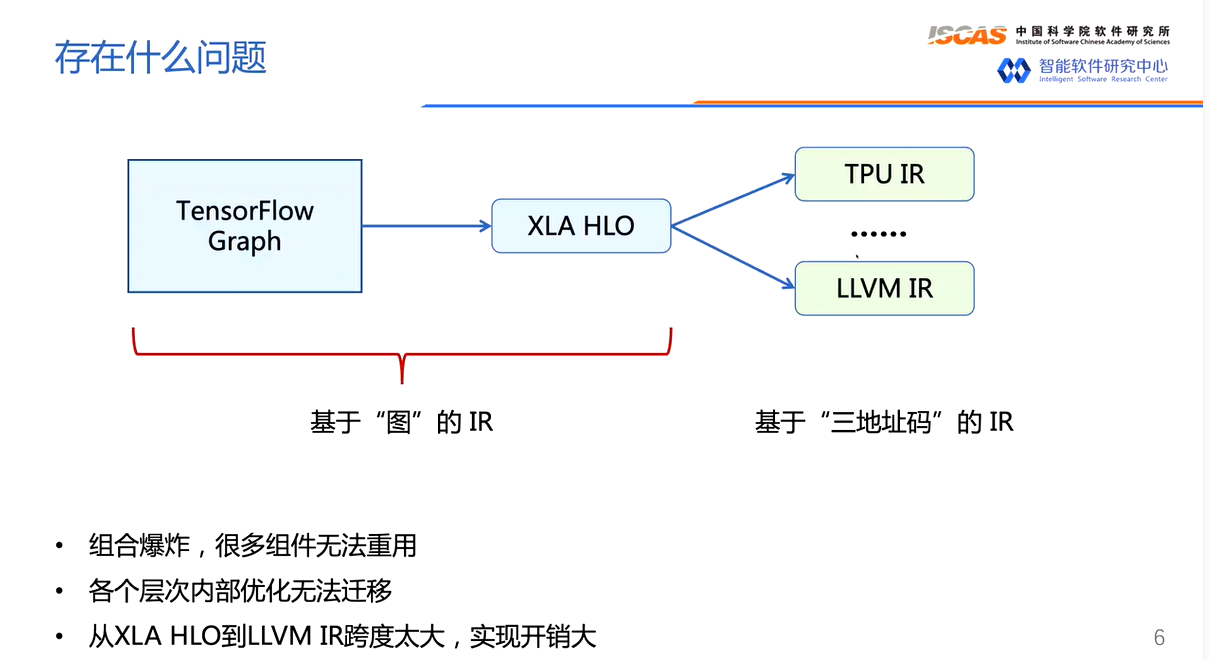
- 第一,IR 的数量太多,开源要维护这么多套 IR,每种 IR 都有自己的图优化 Pass,这些 Pass 可能实现的功能是一样的,但无法在两种不同的 IR 中直接迁移。假设深度学习模型对应的 DAG 一共有 10 种图层优化 Pass,要是为每种 IR 都实现 10 种图层优化 Pass,那工作量是巨大的并且冗余。
- 第二,如果出现了一种新的 IR,开发者想把另外一种 IR 的图层优化 Pass 迁移过来,但由于这两种 IR 语法表示完全不同,除了借鉴优化 Pass 的思路之外,就丝毫不能从另外一种 IR 的 Pass 实现受益了,即互相迁移的难度比较大。此外,如果你想为一个 IR 添加一个 Pass,难度也是不小的。举个例子你可以尝试为 onnx 添加一个图优化 Pass,会发现这并不是一件简单的事,甚至需要我们去较为完整的学习 ONNX 源码。
- 在 Relay 中,添加自定义算子需要 8个步骤,开发人员通常需要花费比较多的时间同时在 C++ 和 Python 里添加一系列的代码。这也是TVM推出Relax的原因之一。
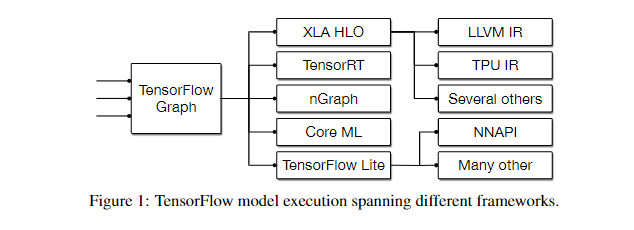
- 第三,以 TensorFlow Graph 为例,它可以直接被转换到 TensorRT 的 IR,nGraph IR,CoreML IR,TensorFlow Lite IR 来直接进行部署。或者 TensorFlow Graph 可以被转为 XLA HLO,然后用 XLA 编译器来对其进行 Graph 级别的优化得到优化后的 XLA HLO,这个 XLA HLO 被喂给 XLA 编译器的后端进行硬件绑定式优化和 Codegen在上面的例子中优化后的 XLA HLO 直接被喂给 XLA 编译器后端产生 LLVM IR 然后 Codegen,这个跨度是非常大的。
Why MLIR
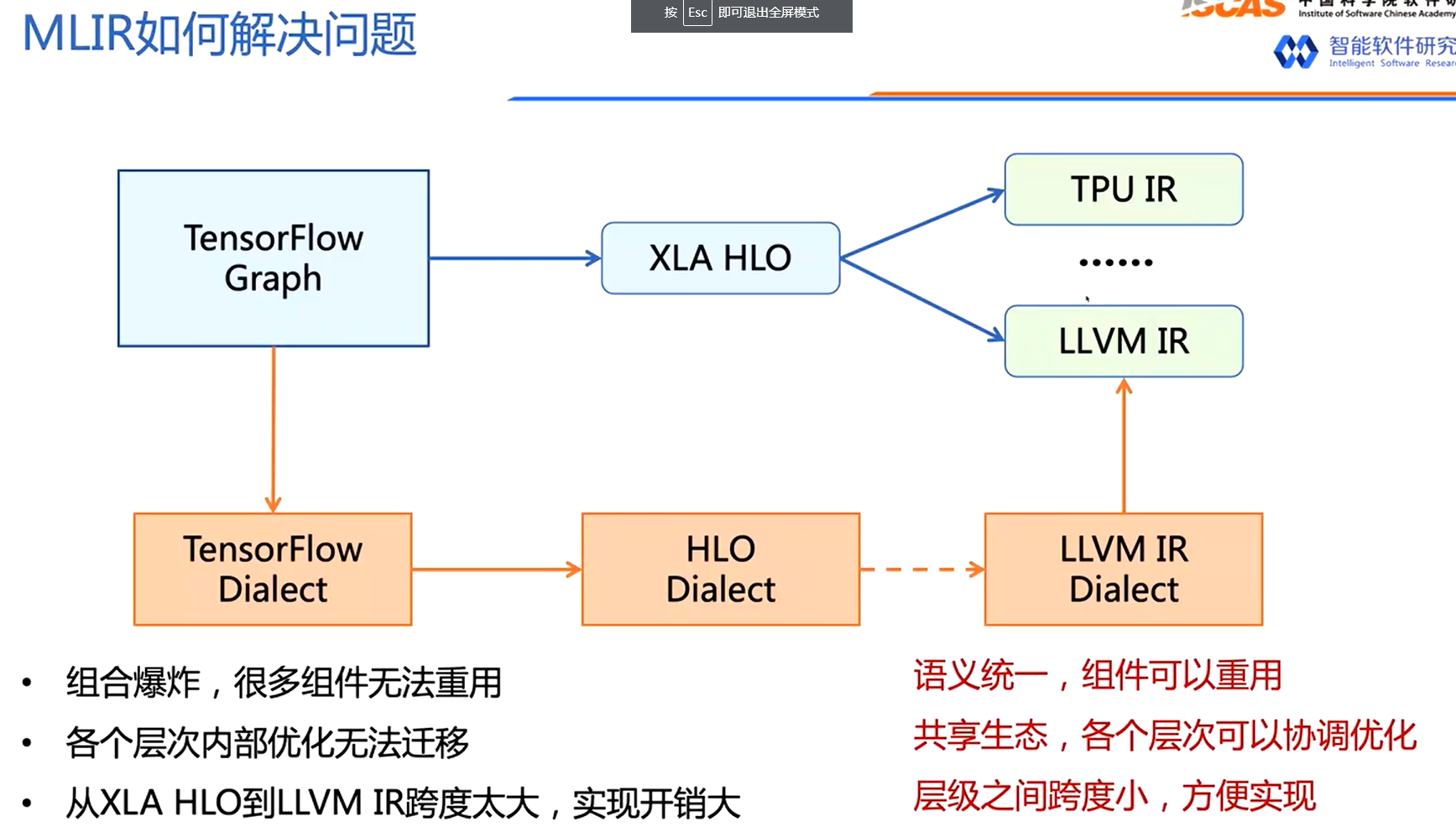
注意图中的虚线并不是一步转化的。
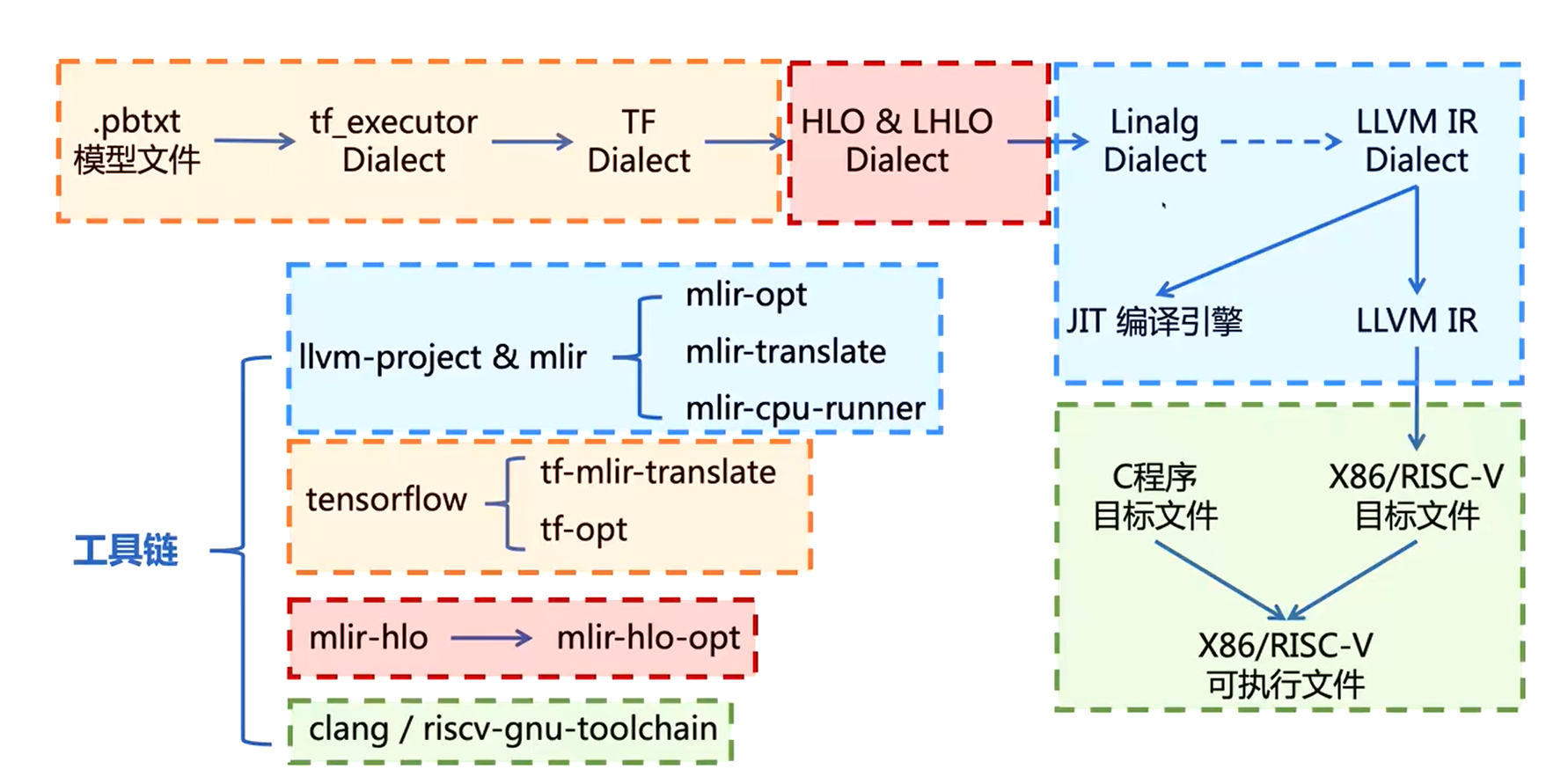
MLIR是一个具有多层IR结构的编译架构,实际上就是多层Dialect,各个Dialect分别对不同的层级概念进行建模。比如LLVM Dialect负责系统级别的转换,Linalg,Tensor,Vector等Dialect负责协同生成代码,而Affine,Math等Dialect用来描述底层计算。
Features
https://zhuanlan.zhihu.com/p/469684807
paper机翻
「内置少,一切可定制(Little builtin, everything customizable)」 MLIR系统基于最少量的基本概念,大部分IR都完全可定制。在设计时,应当用少量抽象(类型、操作和属性,这是IR中最常见的)表示其它所有内容,从而可以使抽象更少、更一致,也让这些抽象易于理解、扩展和使用。
「SSA and regions」 静态单赋值形式[15]是编译器IR中广泛使用的表示形式。它提供了许多优点,包括使数据流分析简单和稀疏,因其与continuation-passing风格的关系而被编译器社区广泛理解,并在主要框架中应用。尽管许多现有的IR使用扁平的,线性CFG,但代表更高级别的抽象却推动将嵌套区域(nested regions)作为IR中的第一概念。
「渐进式降级(Progressive lowering)」 编译系统应支持渐进式lower,即,以较小的步幅,依次经过多个抽象级别,从较高级别的表示降低到最低级别。需要多层抽象是因为通用编译器基础结构必须支持多种平台和编程模型。以前的编译器已经在其pipeline中引入了多个固定的抽象级别,例如Open64 WHIRL表示[30]具有五个级别,Clang/LLVM编译器从AST降级到LLVM IR、SelectionDAG、MachineInstr和MCInst。上述降级实现方式较为僵化,因而需要更灵活的设计来支持抽象级别的可扩展性。这对转换的相位排序有深刻的影响。一般而言,编译器pass可大致分为四个角色:(1)优化变换(2)使能变换(3)lowering(4)cleanup。编译系统应该允许在单个操作的粒度上混合和匹配这些角色,而不是在整个编译单元上顺序执行这些pass。
「保持高层级语意(Maintain higher-level semantics)」 系统需要保留分析或优化性能所需的高级语义和计算结构。一旦降低语义再试图提高语义会很难成功,并且将这种信息强行塞进一个低层次IR的环境中通常都有破坏性(例如,在使用调试信息来记录结构的情况下,所有pass都需要进行验证/重新访问)。
「声明式重写模式(Declarative rewrite patterns)」 定义表示修饰符应该和定义新抽象一样简单。通用变换应实现为声明式表达的重写规则,并以机器可分析的格式推理出重写的属性,例如复杂性和完成度。重写系统的健全性和效率很高,因此被广泛研究,并已被应用于从类型系统(type systems)到指令选择的众多编译问题。
MLIR Basic Concept
Operations(操作)
MLIR中的语义单位是一个“操作”,称为Op。在MLIR系统中,从指令到函数再到模块,一切都建模为Op。 MLIR没有固定的Op集合,因此允许并鼓励用户自定义扩展Op。编译器pass会保守地对待未知Op,并且MLIR支持通过特征(traits)、特殊的Operation hooks和Interfaces等方式为pass描述Op语义。
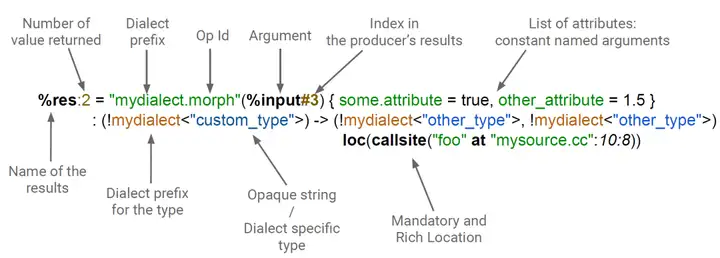
Op(见Figure3)具有唯一的操作码(opcode)。从字面上看,操作码是一个字符串,用于标识它所在的dialect和操作。Op可以有零个或多个值作为操作数和结果,并以静态单赋值的形式(SSA)维护操作数和结果。所有值都有一个类型,类似于LLVM IR。除了操作码、操作数和结果外,Op还可能具有属性、区域、块参数和位置信息(「Attributes, Regions, Block Arguments, and Location Information」)。Figure4说明了值和Op,%标识符是命名值(包),如果包中有多个值,:后指定包中值的数量(注:如Figure3中的%results:2,表示返回值有2个),而“#”表示特定值。在一般的文本表示形式中,操作名称是用引号括起来的字符串,后跟括号括起来的操作数。
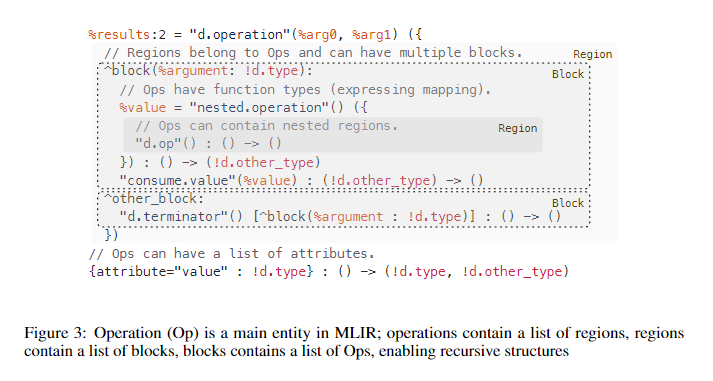

Attributes(属性)
MLIR属性是结构化的编译期静态信息,例如整数常量值、字符串数据或常量浮点值列表。属性有类型,每个Op实例都有一个从字符串名称到属性值的开放键值对字典映射。在通用语法描述中,「属性在Op操作数和其类型之间」,键值对列表中的不同键值对用逗号分隔,并用大括号将整个键值对列表括起来。(如Figure3中的{attribute="value" : !d.type}以及Figure4的{lower_bound = () -> (0), step = 1 : index, upper_bound = #map3})。其中,lower_bound、step和upper_bound是属性名称。() -> (0)标识用于内联仿射形式,在这个例子中是产生常数0的仿射函数。#map3标识用于属性别名,该属性别名允许将属性值与标签预先关联,并可以在任何需要属性值的地方使用标签。与操作码一样,MLIR没有固定的属性集。属性的含义由Op语义或与属性相关的dialect 中得出。属性也是可扩展的,允许直接引用外部数据结构,这对于和现有系统集成很有帮助。例如,某个属性可以引用ML系统中(在编译期已知的)数据存储的内容。
Location information (位置信息)
MLIR提供了位置信息的紧凑表示形式,并鼓励在整个系统中处理和传播位置信息。位置信息可用于保留产生Op的源程序堆栈踪迹,用以生成调试信息。位置信息使编译器产生诊断信息的方式变得标准化,并可用于各种测试工具。位置信息也是可扩展的,允许编译器引用现有的位置跟踪系统、高级AST节点、LLVM风格的文件-行-列(file-line-column )地址、DWARF调试信息或其它高质量编译实现所需的信息。
「上面三个要点我们可以基于Toy语言的transpose Op来加深理解:」
%t_tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1)
结构拆分解释:
%t_tensor:这个Operation定义的结果的名字,前面的%是避免冲突,见https://mlir.llvm.org/docs/LangRef/#identifiers-and-keywords 。一个Operation可以定义0或者多个结果(在Toy语言中,只有单结果的Operation),它们是SSA值。该名称在解析期间使用,但不是持久的(例如,它不会在 SSA 值的内存表示中进行跟踪)。"toy.transpose":Operation的名字。它应该是一个唯一的字符串,Dialect 的命名空间前缀为“.”。 这可以理解为Toy Dialect 中的transpose Operation。(%tensor):零个或多个输入操作数(或参数)的列表,它们是由其它操作定义的SSA值或block参数的引用。{ inplace = true }:零个或多个Attribute的字典,这些属性是始终为常量的特殊操作数。 在这里,我们定义了一个名为“inplace”的布尔属性,它的常量值为 true。(tensor<2x3xf64>) -> tensor<3x2xf64>:函数形式表示的操作类型,前者是输入,后者是输出。<2x3xf64>号中间的内容描述了张量的尺寸2x3和张量中存储的数据类型f64,中间使用x连接。loc("example/file/path":12:1):此操作的源代码中的位置。
Symbols and symbol tables
Op还可以附加一个符号表。这个符号表是将名称(以字符串表示)与IR对象(称为符号)相关联的标准方法。 IR没有规定符号的用途,而是交由Op定义。对于无需遵守静态单赋值规则的命名实体,符号很有用。符号不能在同一表中重复定义,但是可以在定义之前使用符号。例如,全局变量、函数或命名模块可以表示为符号。没有这种机制,就不可能定义递归函数(在定义中引用自己)。如果附带符号表的Op的关联区域包含相似的Op,那么符号表可以嵌套。 MLIR提供了一种机制来引用Op中的符号,包括嵌套符号。
以上为paper机翻,以上概念可以在编程中理解,为了内容完整我把上面内容加进来了,重点在于Dialect.
Dialects
MLIR是一个具有多层IR结构的编译架构,实际上就是多层Dialect,各个Dialect分别对不同的层级概念进行建模。比如LLVM Dialect负责系统级别的转换,Linalg,Tensor,Vector等Dialect负责协同生成代码,而Affine,Math等Dialect用来描述底层计算。
1. Dialect 是什么?
从源程序到目标程序,要经过一系列的抽象以及分析,通过 Lowering Pass 来实现从一个IR到另一个IR的转换。但IR之间的转换需要统一格式,统一IR的第一步就是要统一“语言”,各个IR原来配合不默契,谁也理解不了谁,就是因为“语言”不通。
因此 MLIR 提出了Dialect,各种IR可以转换为对应的 mlir Dialect,不仅方便了转换,而且还能随意扩展。不妨将dialect看成各种具有IR表达能力的黑盒子,之后的编译流程就是在各种dialect之间转化。
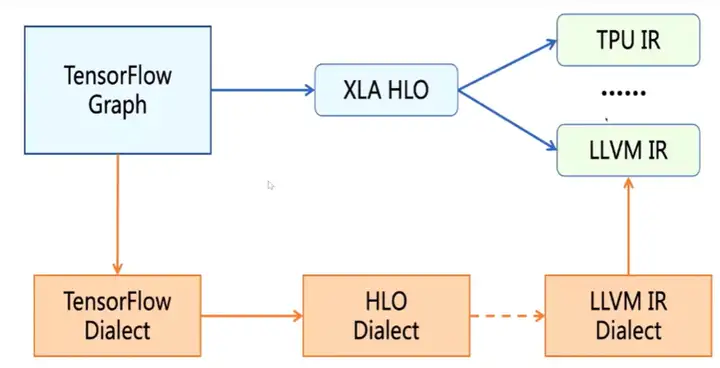
2. dialect 是怎么工作的?
dialect 将所有的IR放在了同一个命名空间中,分别对每个IR定义对应的产生式并绑定相应的操作,从而生成一个MLIR的模型。
每种语言的 dialect(如tensorflow dialect、HLO dialect、LLVM IR dialect)都是继承自 mlir::Dialect,并注册了属性、操作和数据类型,也可以使用虚函数来改变一些通用性行为。
整个的编译过程:从源语言生成 AST(Abstract Syntax Tree,抽象语法树),借助 dialect 遍历 AST,产生 MLIR 表达式(此处可为多层IR通过 Lowering Pass 依次进行分析),最后经过 MLIR 分析器,生成目标硬件程序。
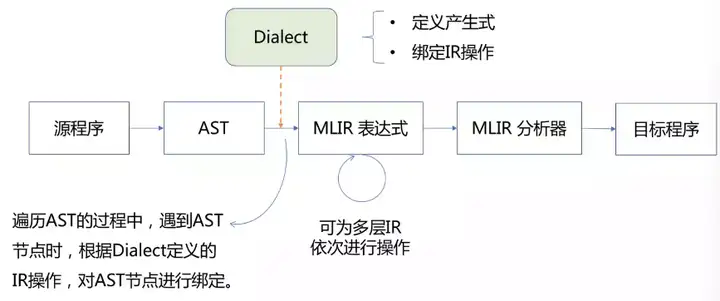
3. dialect 内部构成
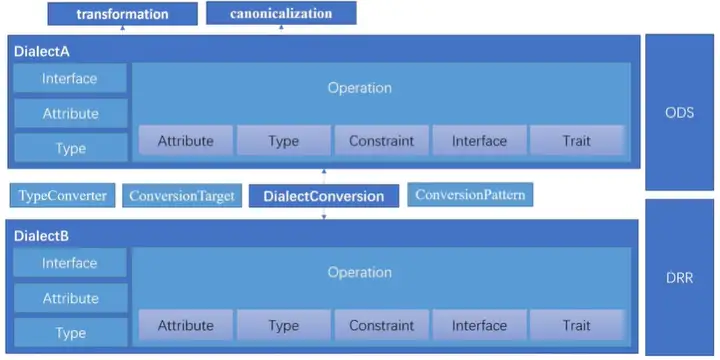
dialect主要是由自定义的 Type、Attribute、Interface 以及 operation 构成。operation 细分为Attribute、Type、Constraint、Interface、Trait(属性、类型、限制、接口、特征)。同时存在 ODS 和 DRR 两个重要的模块,这两个模块都是基于 tableGen 模块,ODS 模块用于定义 operation ,DRR 模块用于实现两个 dialect 之间的 conversion。
ODS 全称 Operation Definition Specification,操作者只需要根据 operation 框架定义的规范,在一个
.td文件中填写相应的内容,使用 mlir 的 tableGen 工具就可以自动生成上面的 C++ 代码。
attribute is structured compile-time static information
MLIR使用Dialect管理可扩展性。Dialect在一个唯一的命名空间下提供Ops、属性和类型的逻辑分组。Dialect本身并未引入任何新的语义,而是用作逻辑分组机制,并且可用于提供Dialect通用Op支持(例如,dialect中所有op的常量折叠行为)。Dialect命名空间在操作码中是以“.”分隔的前缀,例如,Figure 4使用的affine和std dialect。
概念上可以将Ops、类型和属性抽象为Dialect,这类似于设计一组模块化库。例如,某种Dialect可以包含用于对硬件向量进行操作的Op和类型(例如,shuffle、insert/extract元素、掩码等),而另一种Dialect可以包含用于对代数向量进行操作的Op和类型(例如,绝对值、点积等 )。两种dialect是否使用相同的向量类型以及该类型属于哪一个,可以由MLIR用户在设计时决定。
pipeline
接下来会以一个部署例子,一个官方MLIR pipeline形式,一个代码实际演示的例子介绍。
Lowering Pipeline
- from Structured Ops in MLIR - Google 幻灯片
- 在tensor级别fusion通常更简单,因为不需要跟踪对buffer的读取和写入
这个幻灯片非常详细,我会参考这个幻灯片讲解MLIR的lowering逻辑。
MLIR是一个具有多层IR结构的编译架构,实际上就是多层Dialect,各个Dialect分别对不同的层级概念进行建模。比如LLVM Dialect负责系统级别的转换,Linalg,Tensor,Vector等Dialect负责协同生成代码,而Affine,Math等Dialect用来描述底层计算。
One Code Example
- how to use the mlir-opt to lower the operation of matmul to llvm ir
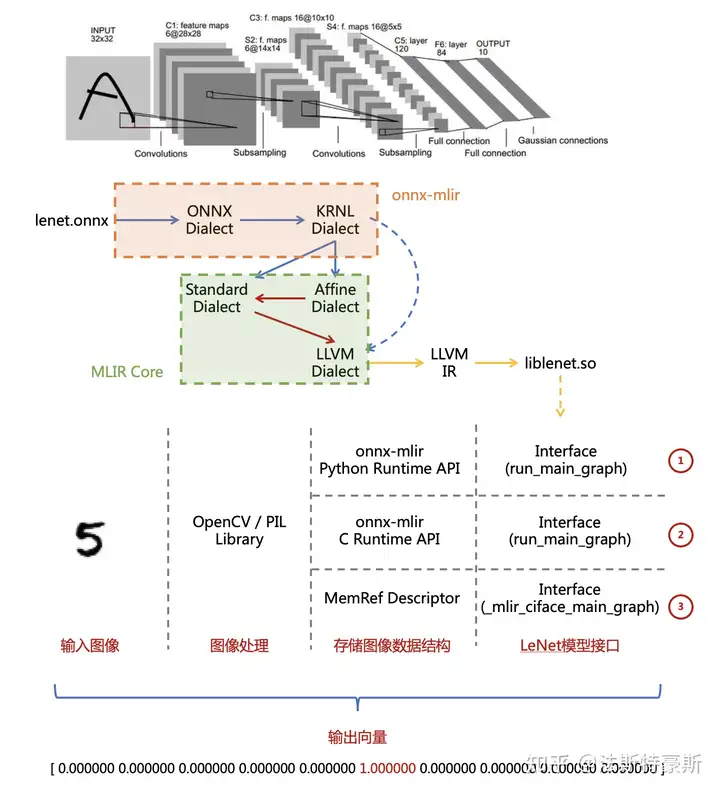
One ONNX Deploy Example
from https://zhuanlan.zhihu.com/p/349912488
ONNX-MLIR可以将ONNX模型接入到MLIR中,并且提供了编译工具以及Python/C Runtime,我们可以使用以下三种方式完成端到端的编译流程:
- Python Runtime + run_main_graph 模型接口
- C Runtime + run_main_graph 模型接口
- MLIR MemRef Descriptor + _mlir_ciface_main_graph 模型接口(MLIR 官方提供)
MLIR官方会把打包出来的动态链接库提供出C可以调用的函数符号。
mlir-opt, mlir-translate
编译MLIR
略
简单介绍编译后的结果
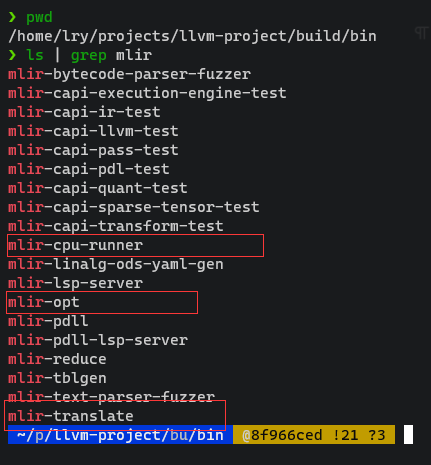
最主要为三个可执行文件:
-
mlir-cpu-runner: 用来运行,JIT直接运行mlir文件
- 可以直接运行“足够底层”的mlir文件(LLVM Dialect)
-
mlir-opt:用来优化,对high level的lower
-
注意mlir-opt各种优化的参数大多数时候都不能改变顺序
-
优化是一层套一层的,dialect之间的转换必须由人工实现代码支持,dialect之间的conversion一般占很大工作量
-
-
mlir-translate: 用来转换成LLVM IR,把MLIR文件转化成LLVM IR
- 注意不是所有的MLIR文件都能转化成LLVM IR,一般需要足够“底层”,基本上都是LLVM Dialect这一步的文件才能转化成LLVM IR。
以下为MLIR的API
${MLIR_OPT} example1.mlir ${MLIR_OPT_OPTIONS} \
--convert-vector-to-scf \
--convert-scf-to-cf \
--convert-linalg-to-llvm \
--lower-affine \
--expand-strided-metadata \
--convert-vector-to-llvm \
--memref-expand \
--arith-expand \
--convert-arith-to-llvm \
--finalize-memref-to-llvm \
--convert-math-to-llvm \
--llvm-request-c-wrappers \
--convert-func-to-llvm \
--reconcile-unrealized-casts \
-o ${OUTFOLDER}/llvm.mlir
${MLIR_TRANSLATE} --mlir-to-llvmir ${OUTFOLDER}/llvm.mlir -o ${OUTFOLDER}/exp1.ll
${MLIR_CPU_RUNNER} ${OPT_FLAG} ${OUTFOLDER}/llvm.mlir -e main -entry-point-result=void \
-shared-libs=${MLIR_RUNNER_UTILS} -shared-libs=${MLIR_C_RUNNER_UTILS}
llc ${OUTFOLDER}/exp1.ll -o ${OUTFOLDER}/exp1.s
MLIR Common Misconceptions
此处值得注意的是,MLIR 本身是基础设施,它负责为 IR 本身和相互的转换提供可重用可扩展的基础结构,它并不负责端到端的任务。MLIR 在深度学习方面端到端的任务可以参考 IREE 和 onnx-mlir,两个项目都是把预训练深度学习模型转换到 MLIR,通过逐层下降到底层 IR,然后提供相应的 runtime 执行到不同的目标硬件上。
How to build one mlir-based compiler?
existing works
- GitHub - buddy-compiler/buddy-mlir: An MLIR-Based Ideas Landing Project 中科院一个toy级别的项目,但是非常容易理解,适合用作参考
-
GitHub - bytedance/byteir: ByteIR 字节一个开源项目,整体架构比较清晰齐全,影响力一般
-
GitHub - onnx/onnx-mlir: Representation and Reference Lowering of ONNX Models in MLIR Compiler Infrastructure 把ONNX接入到MLIR生态, 提供ONNX Dialect.
-
GitHub - openxla/iree: A retargetable MLIR-based machine learning compiler and runtime toolkit.,MLIR-based compiler的目前最有影响力的工作之一.
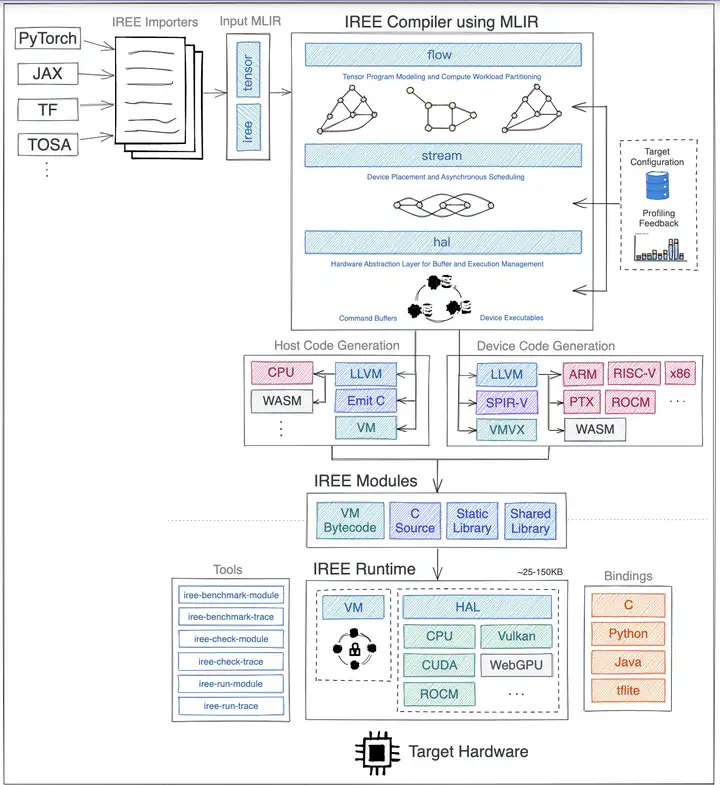
-
GitHub - openai/triton: Development repository for the Triton language and compiler 有一些不同,接入MLIR Dialect生态做优化,利用了其python接口, 以python作为上层语言设计DSL
所以基本上实现一套基于MLIR的编译器比较关键的就是两点:
-
定义Dialect
-
接入我们的Dialect并优化(Conversion)
Triton Walkthrough
Triton pronunciation
trai·tn
define a dialect
from: Defining Dialects - MLIR
在最基本的层面上,在 MLIR 中定义方言就像专门化 C++Dialect类一样简单。MLIR 通过TableGen提供了强大的声明式规范机制 ;具有维护特定领域信息记录的工具的通用语言;它通过自动生成所有必要的样板 C++ 代码来简化定义过程,显着减少更改方言定义方面时的维护负担,并且还提供了额外的工具(例如文档生成)。鉴于上述情况,声明性规范是定义新方言的预期机制.
下面展示了一个Triton的方言定义示例。.td我们通常建议在与方言的属性、操作、类型和其他子组件不同的文件中定义方言类,以在各种不同的方言组件之间建立适当的分层。它还可以防止您无意中为某些构造生成多个定义的情况。此建议扩展到所有 MLIR 构造, 例如包括Interfaces
#ifndef TRITON_DIALECT
#define TRITON_DIALECT
include "mlir/IR/OpBase.td"
def Triton_Dialect : Dialect {
let name = "tt";
let cppNamespace = "::mlir::triton";
let summary = "The Triton IR in MLIR";
let description = [{
Triton Dialect.
Dependent Dialects:
* Arith:
* addf, addi, andi, cmpf, cmpi, divf, fptosi, ...
* Math:
* exp, sin, cos, log, ...
* StructuredControlFlow:
* for, if, while, yield, condition
* ControlFlow:
* br, cond_br
}];
let dependentDialects = [
"arith::ArithDialect",
"math::MathDialect",
"scf::SCFDialect",
"cf::ControlFlowDialect"
];
let extraClassDeclaration = [{
void registerTypes();
}];
let hasConstantMaterializer = 1;
let useDefaultTypePrinterParser = 1;
let usePropertiesForAttributes = 1;
}
include "triton/Dialect/Triton/IR/TritonTypes.td"
#endif // TRITON_DIALECT
每个方言都必须实现一个初始化挂钩,以添加attributes, operations, types, attach any desired interfaces,或为方言执行在构造时应发生的任何其他必要的初始化。以triton为例:
void TritonDialect::initialize() {
registerTypes();
addOperations<
#define GET_OP_LIST
#include "triton/Dialect/Triton/IR/Ops.cpp.inc"
>();
// We can also add interface here.
addInterfaces<TritonInlinerInterface>();
}
operation
我们以其中任意一个op为例,比如说triton自定义的triton loadop operation:
我们写一个triton的操作:
// %arg8: tensor<256x!tt.ptr<f32>>
%6 = arith.cmpi slt, %4, %5 : tensor<256xi32>
%cst_0 = arith.constant 0.000000e+00 : f32
%18 = tt.broadcast %cst_0 : (f32) -> tensor<256xf32>
%19 = tt.load %arg8, %6, %18 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<256xf32>
以上为从一个MLIR代码中抽取的一段代码,其实现了从一个tensor的指针中load选定的值。
我们会在TritonOps.td中定义这样一个operation:
//
// Load/Store Ops
//
def TT_LoadOp : TT_Op<"load",
[SameLoadStoreOperandsAndResultShape,
SameLoadStoreOperandsAndResultEncoding,
AttrSizedOperandSegments,
DeclareOpInterfaceMethods<MemoryEffectsOpInterface>,
TypesMatchWith<"infer ptr type from result type",
"result", "ptr", "$_self",
"mlir::OpTrait::impl::verifyLoadStorePointerAndValueType">,
TypesMatchWith<"infer mask type from result type or none",
"result", "mask", "getI1SameShape($_self)",
"($_op.getOperands().size() <= 1) || std::equal_to<>()">,
TypesMatchWith<"infer other type from result type or none",
"result", "other", "$_self",
"($_op.getOperands().size() <= 2) || std::equal_to<>()">]> {
let summary = "Load from a tensor of pointers or from a tensor pointer";
let arguments = (ins AnyTypeOf<[TT_PtrLike, TT_TensorPtr]>:$ptr, Optional<TT_BoolLike>:$mask,
Optional<TT_Type>:$other, OptionalAttr<DenseI32ArrayAttr>:$boundaryCheck,
OptionalAttr<TT_PaddingOptionAttr>:$padding, TT_CacheModifierAttr:$cache,
TT_EvictionPolicyAttr:$evict, BoolAttr:$isVolatile);
let results = (outs TT_Type:$result);
let builders = [
// A tensor of pointers or a pointer to a scalar
OpBuilder<(ins "Value":$ptr, "triton::CacheModifier":$cache,
"triton::EvictionPolicy":$evict, "bool":$isVolatile)>,
// A tensor pointer with boundary check and padding
OpBuilder<(ins "Value":$ptr, "ArrayRef<int32_t>":$boundaryCheck,
"std::optional<triton::PaddingOption>":$padding, "triton::CacheModifier":$cache,
"triton::EvictionPolicy":$evict, "bool":$isVolatile)>,
// A tensor of pointers or a pointer to a scalar with mask
OpBuilder<(ins "Value":$ptr, "Value":$mask, "triton::CacheModifier":$cache,
"triton::EvictionPolicy":$evict, "bool":$isVolatile)>,
// A tensor of pointers or a pointer to a scalar with mask and other
OpBuilder<(ins "Value":$ptr, "Value":$mask, "Value":$other, "triton::CacheModifier":$cache,
"triton::EvictionPolicy":$evict, "bool":$isVolatile)>,
// A utility function to build the operation with all attributes
OpBuilder<(ins "Value":$ptr, "Value":$mask, "Value":$other,
"std::optional<ArrayRef<int32_t>>":$boundaryCheck,
"std::optional<triton::PaddingOption>":$padding, "triton::CacheModifier":$cache,
"triton::EvictionPolicy":$evict, "bool":$isVolatile)>
];
// Format: `tt.load operands attrs : optional(type(ptr)) -> type(result)`
// We need an extra `optional(type(ptr))` for inferring the tensor pointer type with back compatibility
let hasCustomAssemblyFormat = 1;
let hasCanonicalizer = 1;
}
其余有关Attr, type的tablegen不一一赘述,大同小异。
Logic of Optimize and Conversion
原理上我们可以通过编写Pattern,继承mlir::RewritePattern类作为父类,然后编写对应的虚函数接口matchAndRewrite实现Dialect的转换和优化。
Example 1 Dialect optimize
我们以上面提到的LoadOp为例,观看更高层级的op如何进一步优化为Triton的op:
我们以lib/Dialect/Triton/Transforms/Combine.cpp为例:
// select(cond, load(ptrs, broadcast(cond), ???), other)
// => load(ptrs, broadcast(cond), other)
class CombineSelectMaskedLoadPattern : public mlir::RewritePattern {
public:
CombineSelectMaskedLoadPattern(mlir::MLIRContext *context)
: mlir::RewritePattern(mlir::arith::SelectOp::getOperationName(), 3,
context, {triton::LoadOp::getOperationName()}) {}
mlir::LogicalResult
matchAndRewrite(mlir::Operation *op,
mlir::PatternRewriter &rewriter) const override {
auto selectOp = llvm::dyn_cast<mlir::arith::SelectOp>(op);
if (!selectOp)
return mlir::failure();
mlir::Value trueValue = selectOp.getTrueValue();
mlir::Value falseValue = selectOp.getFalseValue();
mlir::Value condSelect = selectOp.getCondition();
auto *loadOpCandidate = trueValue.getDefiningOp();
auto loadOp = llvm::dyn_cast_or_null<triton::LoadOp>(loadOpCandidate);
if (!loadOp)
return mlir::failure();
mlir::Value mask = loadOp.getMask();
if (!mask)
return mlir::failure();
auto *broadcastOpCandidate = mask.getDefiningOp();
auto broadcastOp =
llvm::dyn_cast_or_null<triton::BroadcastOp>(broadcastOpCandidate);
if (!broadcastOp)
return mlir::failure();
auto broadcastCond = broadcastOp.getSrc();
if (broadcastCond != condSelect)
return mlir::failure();
rewriter.replaceOpWithNewOp<triton::LoadOp>(
op, loadOp.getPtr(), loadOp.getMask(), falseValue,
loadOp.getBoundaryCheck(), loadOp.getPadding(), loadOp.getCache(),
loadOp.getEvict(), loadOp.getIsVolatile());
return mlir::success();
}
};
Example 2 dialect conversion
Triton All Dialect
triton自己定义了Triton, TritonGPU, TritonNvidiaGPU, NVGPU四个Dialect,NVGPU, TritonNvidiaGPU应该是后来加的,目前conversion部分定义了NVGPUToLLVM TritonGPUToLLVM TritonToTritonGPU这么几个Conversion,目前来看其最High level的dialect应该是Triton Dialect, 然后是TritonGPU较为底层,我们目前只需要focus这两个dialect.
注意Triton是使用MLIR重写了,之前是Triton自己定义的一个IR,而后拆解成了Triton Dialect和TritonGPU Dialect双层体系,把更多和底层优化相关的细节下沉到Triton GPU Dialect上,使得整个系统的设计更加清晰。另一方面,也得益于MLIR的现有生态,复用了相当一部分MLIR已有的基础设施,比如Tensor/SCF/Arith/Math/Standard等等Dialects,以及一些相对基础的优化pass,比如LICM, CSE等等.
Conversion logic
dialect之间conversion一般都在lib/Conversion里面,比如说Triton->TritonGPU
就在对应的lib/Conversion/TritonToTritonGPU/TritonToTritonGPUPass.cpp,而转化的逻辑此处为继承OpConversionPattern的模板类,然后也是重写父类函数matchAndRewrite.
struct TritonDotPattern : public OpConversionPattern<triton::DotOp> {
using OpConversionPattern<triton::DotOp>::OpConversionPattern;
LogicalResult
matchAndRewrite(triton::DotOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
RankedTensorType origType = op.getType().cast<RankedTensorType>();
auto origShape = origType.getShape();
auto typeConverter = getTypeConverter<TritonGPUTypeConverter>();
int numWarps = typeConverter->getNumWarps();
int threadsPerWarp = typeConverter->getThreadsPerWarp();
int numCTAs = typeConverter->getNumCTAs();
SmallVector<unsigned> retSizePerThread = {1, 1};
if (origShape[0] * origShape[1] / (numWarps * threadsPerWarp) >= 4)
retSizePerThread = {2, 2};
if (origShape[0] * origShape[1] / (numWarps * threadsPerWarp) >= 16)
retSizePerThread = {4, 4};
SmallVector<unsigned> retOrder = {1, 0};
Attribute dEncoding = triton::gpu::BlockedEncodingAttr::get(
getContext(), origShape, retSizePerThread, retOrder, numWarps,
threadsPerWarp, numCTAs);
RankedTensorType retType =
RankedTensorType::get(origShape, origType.getElementType(), dEncoding);
// a & b must be of smem layout
auto aType = adaptor.getA().getType().cast<RankedTensorType>();
auto bType = adaptor.getB().getType().cast<RankedTensorType>();
Type aEltType = aType.getElementType();
Type bEltType = bType.getElementType();
Attribute aEncoding = aType.getEncoding();
Attribute bEncoding = bType.getEncoding();
if (!aEncoding || !bEncoding)
return failure();
Value a = adaptor.getA();
Value b = adaptor.getB();
Value c = adaptor.getC();
if (!aEncoding.isa<triton::gpu::DotOperandEncodingAttr>()) {
Attribute encoding = triton::gpu::DotOperandEncodingAttr::get(
getContext(), 0, dEncoding, aEltType);
auto dstType =
RankedTensorType::get(aType.getShape(), aEltType, encoding);
a = rewriter.create<triton::gpu::ConvertLayoutOp>(a.getLoc(), dstType, a);
}
if (!bEncoding.isa<triton::gpu::DotOperandEncodingAttr>()) {
Attribute encoding = triton::gpu::DotOperandEncodingAttr::get(
getContext(), 1, dEncoding, bEltType);
auto dstType =
RankedTensorType::get(bType.getShape(), bEltType, encoding);
b = rewriter.create<triton::gpu::ConvertLayoutOp>(b.getLoc(), dstType, b);
}
c = rewriter.create<triton::gpu::ConvertLayoutOp>(c.getLoc(), retType, c);
addNamedAttrs(rewriter.replaceOpWithNewOp<triton::DotOp>(
op, retType, a, b, c, adaptor.getAllowTF32()),
adaptor.getAttributes());
return success();
}
};
Target-Translate
从Python ast -> Triton IR-> Triton GPU IR 之后,我们需要mlir-translate这样的工具把mlir转化成LLVM IR,而triton此处提供了两个工具,分别支持LLVM
拿到最底层的TritonGPU IR 之后,目前Triton是主要NV GPU上开发,它提供了两个工具用于TritonGPU IR -> LLVM IR -> NVPTX.
std::unique_ptr<llvm::Module>
translateTritonGPUToLLVMIR(lvm::LLVMContext *llvmContext,
mlir::ModuleOp module, int computeCapability,
mlir::triton::gpu::TMAMetadataTy &tmaInfos,
Target target)
std::string translateLLVMIRToPTX(llvm::Module &module, int cc, int version) {
Triton not only one MLIR-based compiler but more a language
DSL in deed
本质上来说,Triton和TVM/XLA这类工作的定位有所不同,如果说TVM/XLA是比较纯正的AI编译器的话,Triton更像是一个面向AI加速器算子开发的领域开发语言,为了能够将用户使用Triton语言开发的kernel映射到具体硬件上的执行码,需要设计开发相应的Triton compiler来完成这层映射。所以当我们说Triton的时候,其实隐指了Triton语言+Triton编译器这两个事物的综合体。
Triton语言的语法并不复杂,在这篇文档里能够看到,大约只有50条左右的新增操作。当然Triton是嵌入在Python这一宿主语言里,也复用了Python的一部分语言表达能力,比如上面例子里的for loop, 以及基本的 +=, , //等算术操作。Triton从Python DSL到Triton底层IR的映射过程是通过解析Python AST来完成的,所以并不是所有的Python写法都可以支持。
Integration to Python
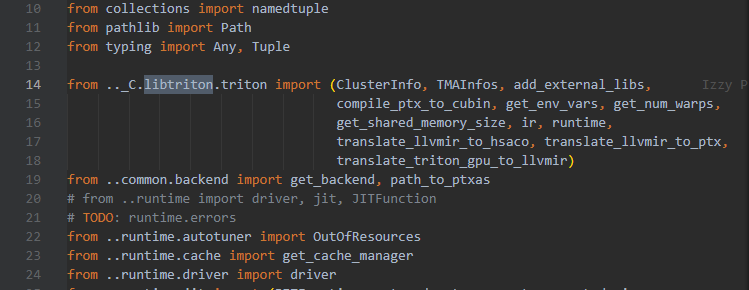
triton是将mlir打包成了动态链接库libtriton.so,然后在python中直接调用mlir内部所拥有的优化以及自己定义的IR,也就是triton其实本质上是一个基于python的DSL,它的所有workflow是python端完成的。
Triton Example
可以参考python/tutorials,里面有大量的官方例子可以参考。注意triton为python api,所以例子全部由python书写完成。
Triton Meeting
-
资料太少,没有很形象的图。
-
原始论文是基于的很早之前的非MLIR版本。
-
个人整理,难免有错误或者疏漏。
-
最近9月会有一个triton的meeting,可以注册报名。
- Registration Link for Triton Developer Conference is here
S2 Chip Support?
Triton WorkFlow
Python ast -> Triton IR-> Triton GPU IR -> LLVM IR -> NV PTX(NV GPU 开源最底层汇编)
然后由CUDA的闭源汇编器将NV PTX翻译成对应架构的汇编。
S2编译器可以直接把LLVM IR翻译成机器码,所以省略掉了PTX的转化。
开发一个可用版本,S2 Compiler至少需要完成:
-
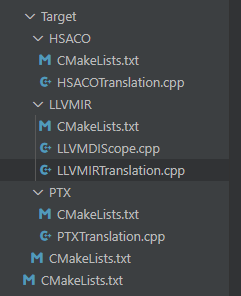
Triton GPU IR -> LLVM IR 的Translation,也即
lib/Target/LLVMIR/LLVMIRTranslation.cpp, 并且适当改动一些high level的映射。 -
对python端的runtime等一些workflow做适配(triton几乎整个workflow都是python完成的)。
More
triton python 解析